
摘要: 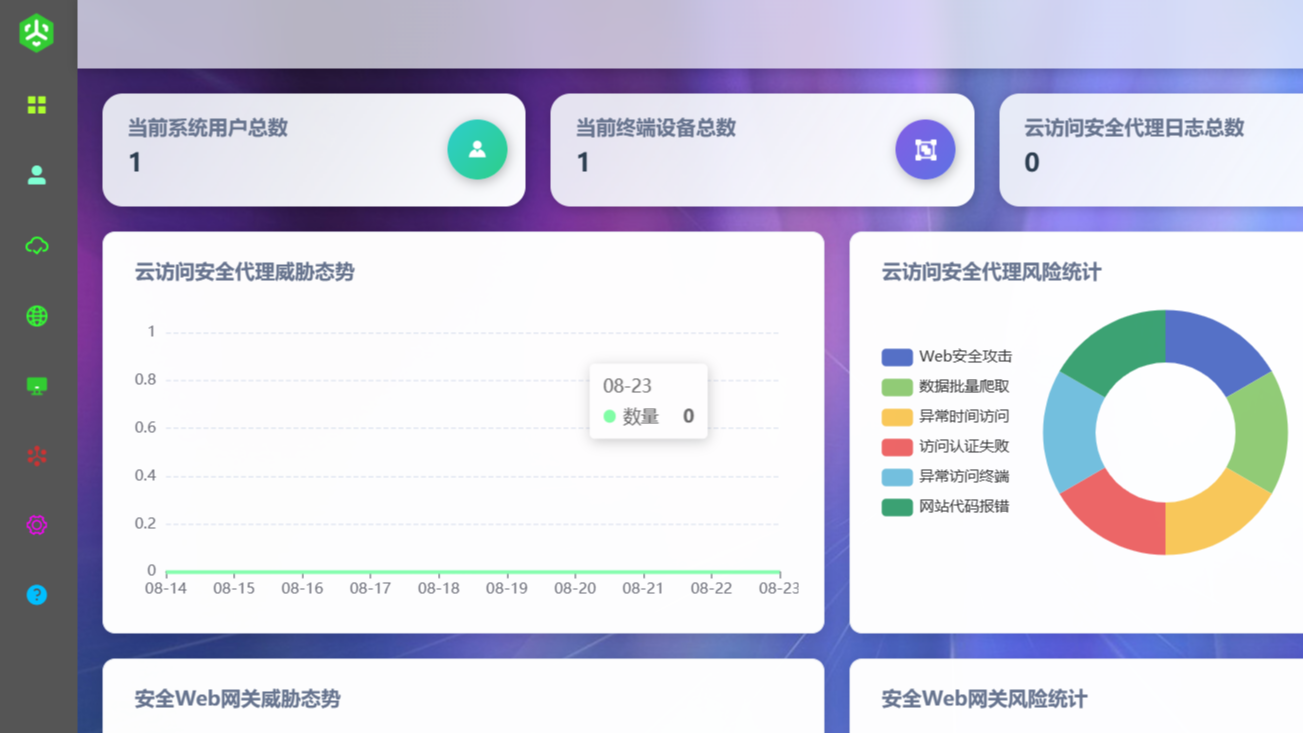 天机 办公安全网关(简称:TJOSG)是有安科技推出的一款全方位办公安全防护产品。既可以通过天机的云访问安全代理(CASB)功能有效保护各种办公服务,包括但不限于OA、ERP、HR、BOSS等办公系统的数据水印、数据脱敏、异常检测,又能通过天机的安全Web网关(SWG)对外对员工上网行为进行安全管控 阅读全文
天机 办公安全网关(简称:TJOSG)是有安科技推出的一款全方位办公安全防护产品。既可以通过天机的云访问安全代理(CASB)功能有效保护各种办公服务,包括但不限于OA、ERP、HR、BOSS等办公系统的数据水印、数据脱敏、异常检测,又能通过天机的安全Web网关(SWG)对外对员工上网行为进行安全管控 阅读全文
天机 办公安全网关(简称:TJOSG)是有安科技推出的一款全方位办公安全防护产品。既可以通过天机的云访问安全代理(CASB)功能有效保护各种办公服务,包括但不限于OA、ERP、HR、BOSS等办公系统的数据水印、数据脱敏、异常检测,又能通过天机的安全Web网关(SWG)对外对员工上网行为进行安全管控 阅读全文
摘要: 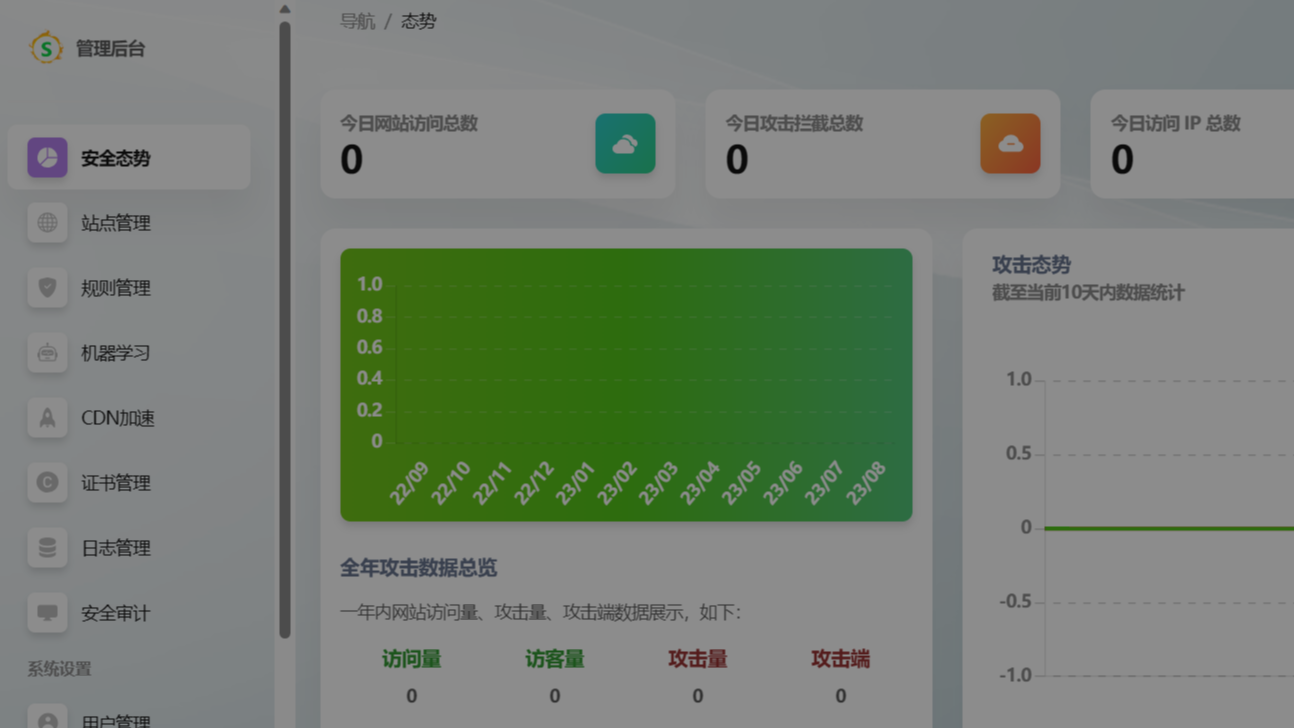 免费的web应用防火墙最出名的非ModSecurity莫属。ModSecurity一度以维护者众多,规则更新较积极,并且免费而受安全圈追捧,然而随着时代变迁,ModSecurity的多种致命缺陷也逐渐暴露,包括: 缺乏管理后台,使用起来极为不便。 安全规则过于粗糙,很容易产生误报,从而影响正常业务。 阅读全文
免费的web应用防火墙最出名的非ModSecurity莫属。ModSecurity一度以维护者众多,规则更新较积极,并且免费而受安全圈追捧,然而随着时代变迁,ModSecurity的多种致命缺陷也逐渐暴露,包括: 缺乏管理后台,使用起来极为不便。 安全规则过于粗糙,很容易产生误报,从而影响正常业务。 阅读全文
免费的web应用防火墙最出名的非ModSecurity莫属。ModSecurity一度以维护者众多,规则更新较积极,并且免费而受安全圈追捧,然而随着时代变迁,ModSecurity的多种致命缺陷也逐渐暴露,包括: 缺乏管理后台,使用起来极为不便。 安全规则过于粗糙,很容易产生误报,从而影响正常业务。 阅读全文
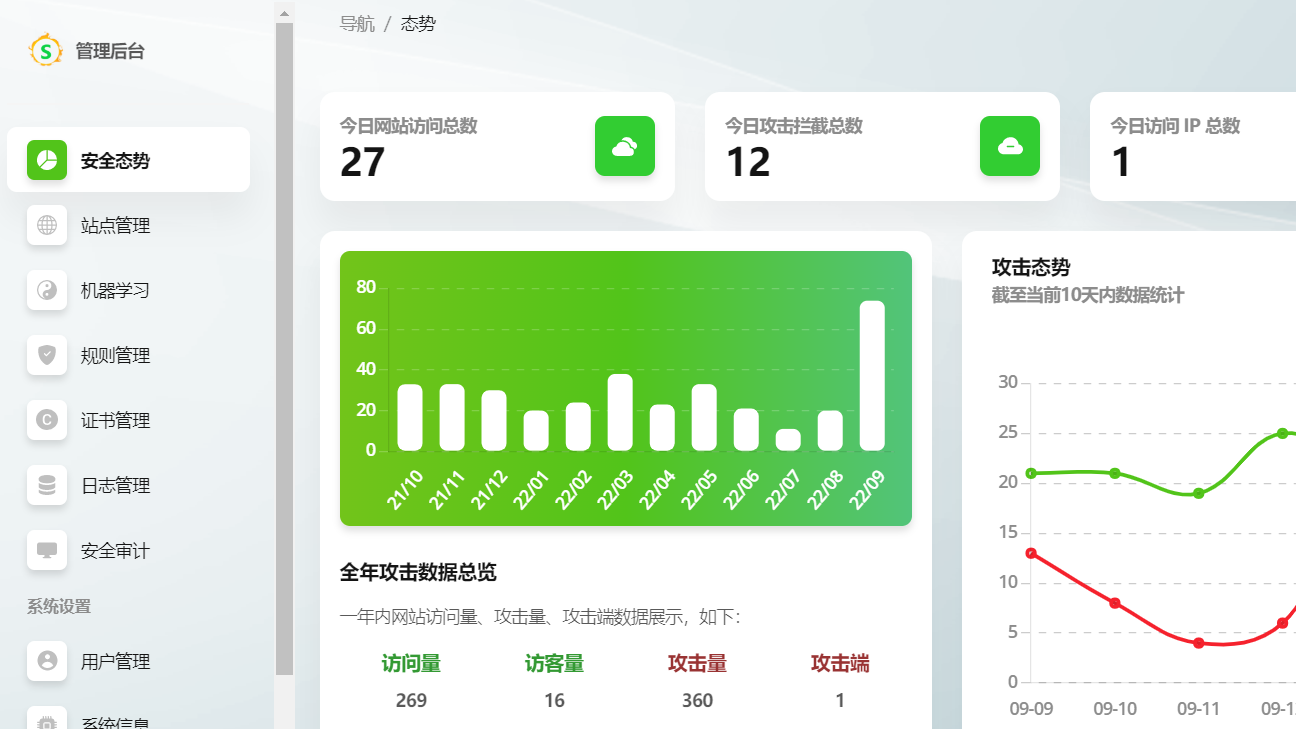 免费的web应用防火墙最出名的非ModSecurity莫属。ModSecurity一度以维护者众多,规则更新较积极,并且免费而受安全圈追捧,然而随着时代变迁,ModSecurity的多种致命缺陷也逐渐暴露,包括: 缺乏管理后台,使用起来极为不便。 安全规则过于粗糙,很容易产生误报,从而影响正常业务。
免费的web应用防火墙最出名的非ModSecurity莫属。ModSecurity一度以维护者众多,规则更新较积极,并且免费而受安全圈追捧,然而随着时代变迁,ModSecurity的多种致命缺陷也逐渐暴露,包括: 缺乏管理后台,使用起来极为不便。 安全规则过于粗糙,很容易产生误报,从而影响正常业务。